As part of Boba Quest 2025 🧋, I'm trying and reviewing a new boba shop each week.
I'm on vacation this week in San José, California, so I'm taking a break from Boba Quest — just kidding, of course I wanted to review another boba shop.
Back in October 2019 I was the executive editor of the Spartan Daily, San José State's student newspaper, when we published our "Boba Bloom" issue. It discussed the financial and health impacts of boba, profiled an alumnus who started their own shop, and most importantly, reviewed and ranked multiple boba shops around campus.
The winner? Breaktime Tea, at 110 East San Fernando St. It's about a block away from the VTA light rail Paseo de San Antonio station, which is accessible using the Blue and Green lines.
To this day, Breaktime still has that ranking prominently displayed for students to see that yes, they are (or were) the best.
Aside from a small tear, the newspaper print has held up. The digital version will be easier to read though.
Somehow it's already been five years since that issue was printed, but I wanted to see how things were today.
I asked for what I had always gotten: a lychee green milk tea with boba. They actually didn't have it on the menu, only advertising a lychee green tea (i.e. no milk) but when I talked to one of the employees, they said it was only recently changed, and they could still make the old drink for me.
Lychee green milk tea on the left, and a mango mojito with lychee jelly (not reviewed) on the right.
Boba: 4/4 the boba was perfect, it had the ideal consistency and right amount of sweetness. The tea also comes with small lychee fruit bits, which is just icing on top of the cake.
Tea: 4/4 lychee is one of my favorite fruits, but it's rare to find a place that offers it as a milk tea. Apparently Breaktime no longer fits in that category, but this was exactly what I wanted.
Bonus: 1/1 the ambiance and experience is really nice, I've spent enough time there drinking boba and chatting with friends.
Consistency: 1/1 I had intended for the consistency point to be awarded after a shop gets a 9/10 score, but given that I've been drinking here for 5+ years, I'm going to make an exception. I was genuinely stunned that it tasted basically the exact same from what I remember when I was a college student.
Total: 10/10. Breaktime earns our first 10/10 score! I'm not surprised, my experience with them as a student was always top-notch and I'm really glad to see it continue.
I'll be back in New York City next week, and am planning to kick-off March with a review from within the five boroughs.
P.S. I'm working on a better website to showcase these reviews, if you want a sneak preview. I still need to improve some things like the mobile view and no-JavaScript fallbacks, but any feedback would be welcome.
This week's review is a bit different as it, unfortunately, is the first boba shop I didn't reach by public transit. We visited Boba Baar in Garden City on Long Island.
You technically can get there by taking the Long Island Rail Road to Mineola, then catching the n22 bus to the Roosevelt Field Mall, and then walking half a mile to Boba Baar. Or take LIRR to Carle Place and then walk 1.5 miles. Point is, it's pretty inconvenient to get to from the city.
But Boba Baar seemed promising at first, a literal thirst trap.
Basically the first thing you see when you walk in.
The shop itself had really nice ambiance; while we waited for our drinks, we got in a few rounds of Mortal Kombat II.
Boba Baar posted their top 10 drinks, and the first one listed was a cookies and cream milk tea. I was tempted to try it, but Kajol, my girlfriend, was more interested in trying the tiramisu milk tea, which people had, surprisingly, positively mentioned on the Google reviews.
In the end, I ordered a more traditional thai milk tea with brown sugar. It was:
Boba: 1/4 the boba was overcooked and pretty flavorless.
Tea: 4/4 on the flip side, the tea was quite good, it tasted like a normal thai milk tea, but with a nice bit of brown sugar mixed in.
Bonus: 0/1 the ambiance was quite nice, but it's just too hard to reach without a car.
Total: 5/10. I was disappointed, they've clearly put a lot of thought into building a nice space for people on Long Island, but the boba was a let down.
Kajol ordered the tiramisu milk tea. Her review:
Boba: 2/4 the boba wasn’t consistent and was very chewy.
Tea: 2/4 it was good and sweet but it didn’t taste like tiramisu at all and I’m not really sure what it did taste like.
Bonus: 1/1 there were very unique flavor options along with dairy-free options. The place was also decorated really well and had plenty of seating for people to hang out or study.
Total: 5/10. Kajol further said she would return to try a different flavor, maybe something more classic that would allow for better comparison (like the brown sugar boba) but wouldn’t return for the tiramisu boba.
I, Kunal, tried the so-called "tiramisu milk tea" as well and have yet to figure out what it actually tasted like, but it definitely was not tiramisu.
I've been using my reMarkable 2 a lot more recently, and have gotten started with actually hacking on it. It's a bit overdue, since the main reason I purchased it in the first place was that it is built on top of Linux and doesn't require any special jailbreaking/rooting.
I found Adrian Daerr's script to import PDFs/EPUBs into a reMarkable, which is surprisingly not a straightforward operation.
You need to rename the file to use a UUID as its name, create corresponding .metadata and .content files, and then empty .cache, .highlights, and .thumbnails directories.
Daerr's bash script does all of this, except it runs on a different machine, and then scps the files over to the reMarkable. Modifying it to run on the reMarkable itself didn't seem too complicated, but I try to avoid writing shell scripts as much as possible, so I took the opportunity to port it to Rust.
I first asked Claude to port it to Rust, and, probably for the first time, I was disappointed by the result.
I couldn't come up with a reason on why Claude would insert a comma after the equals sign (it's not really a hallucination I think?), but rust-analyzer flagged it as a syntax error right away.
I deleted most of that code anyways since I wanted to unconditionally restart, and also use camino instead. As an aside, std::path represents paths with OsString, which is incredibly inconvenient to use anywhere else, which'll expect normal UTF-8 Strings. camino only supports paths that are fully UTF-8 (aka String instead of OsString), which should be fine for most projects that don't need to support legacy files and encodings, like this one.
Next, I had to cross-build it for the reMarkable's ARM v7 CPU. I've done it before for Raspberry Pis, but since it's been a while, I wanted to try out the cross tool, which transparently builds in a container with the necessary toolchains. And if you set a little bit of metadata, it's as simple as cross build --release.
To make the newly imported file actually show up in the reMarkable file listing, you apparently have to restart the entire thing, which does work, but surely there's a better way to tell it to look for new files...
Finally, to actually make use of it, I set up rclone to automatically fetch a folder from my Nextcloud instance, and then run rm-import over it. And now I can drop a PDF in a dedicated Nextcloud folder, and it'll end up on my reMarkable!
Over the past month, Freedom of the Press Foundation has received significant interest in newsrooms setting up SecureDrop. Our open source whistleblower submission system is already used around the globe by large media organizations, small nonprofit newsrooms, and everything in between. We’re excited to see more adoption of SecureDrop.
To help newsrooms better understand both what makes SecureDrop special, as well as what it takes to operate it, we’ve published a guide highlighting five things to know; check out the full post on the SecureDrop blog.
When we walked in, they had a sign for their New Year special: a camellia ruby pomelo tea. I'm a big fan of pomelo, or પપનસ in Gujarati, since we regularly ate it as kids. If you haven't tried it before, it's similar to a grapefruit, but better. And as I just learned, pomelo is also part of Lunar New Year celebrations. Here's the entire tea description on the menu:
Red pomelo is more than a fruit, it's a celebration of the New Year. Its vibrant red symbolizes abundance and togetherness, while its bright, tangy sweetness bursts with freshness. Subtle notes of camellia and osmanthus add elegance, blending festive joy with the warmth of home. Fresh yet unique, it redefines the pomelo experience.
A vibrant and citrusy drink featuring freshly brewed Taiwan camellia oolong tea, juicy seasonal Florida ruby pomelo, and a handcrafted natural plant-based osmanthus jelly. Hand-peeled pomelo segments add a delightful burst of freshness to this floral and aromatic blend.
As I've mentioned before, I much prefer milk teas, but since this was a special, limited edition drink I was willing to give it a try. And, it paid off.
Boba: 4/4 perfect chewiness and sweetness. The jelly was a nice complementary texture in between the boba and the pomelo pieces.
Tea: 4/4 it tasted exactly like the description: pomelo juice with subtle amounts of oolong tea. I've not enjoyed lemon teas in the past, so I was genuinely surprised at how much I liked this.
Bonus: 1/1 it was not well advertised, but they do have a privacy-friendly stamp card! It took a minute for one of the workers to find the cards when I asked, so probably not enough people take them up on it.
Total: 9/10. We have our first complete score! It is incredibly well deserved, it sounds cheesy but for a few hours after I finished the tea I was telling my girlfriend, Kajol, that I couldn't stop thinking about the tea and wanted more. Speaking of Kajol, she ordered a "BOBO milk tea" (brown sugar boba) with light ice. By default it came with lactose-free milk.
Boba: 4/4 good amount of QQ, good flavor
Tea: 4/4 tea flavor is good, perfect amount for her (not too strong, not too mild, not too sweet)
Bonus: 1/1 the place is aesthetic and it was nice that they had different lactose free milk options. We had to order on a self-checkout kiosk, but there are interesting and different options from other places. The container was cute but she wished it was bigger.
Before we total up the score, we need to discuss what happened with the boba cups:
Biggest regret: not taking a better picture of the teas right after we bought them.
There was a minor accident and my tea cup was dropped right as we entered my apartment. The bottom cracked so I dumped the tea into the closest jar to me, salvaging nearly all of it. On the other hand, Kajol's tea came in quite a robust plastic mason jar that didn't break. It definitely is small compared to what you normally get at other boba shops.
Back to the total score: 9/10, another complete score!
As I had explained when I first laid out the rating system, the tenth and final point is for consistency. After earning a 9/10, I'll go back and if keeps up the same level of quality, then the score will be increased to a perfect 10/10.
I will likely wait until the summer to officially retry Débutea (and other 9/10 shops) and have some vague plans about inviting a bigger group of people to get broader feedback. But also I'm probably going to go back this weekend just so I can have the camellia ruby pomelo tea again before it goes away.
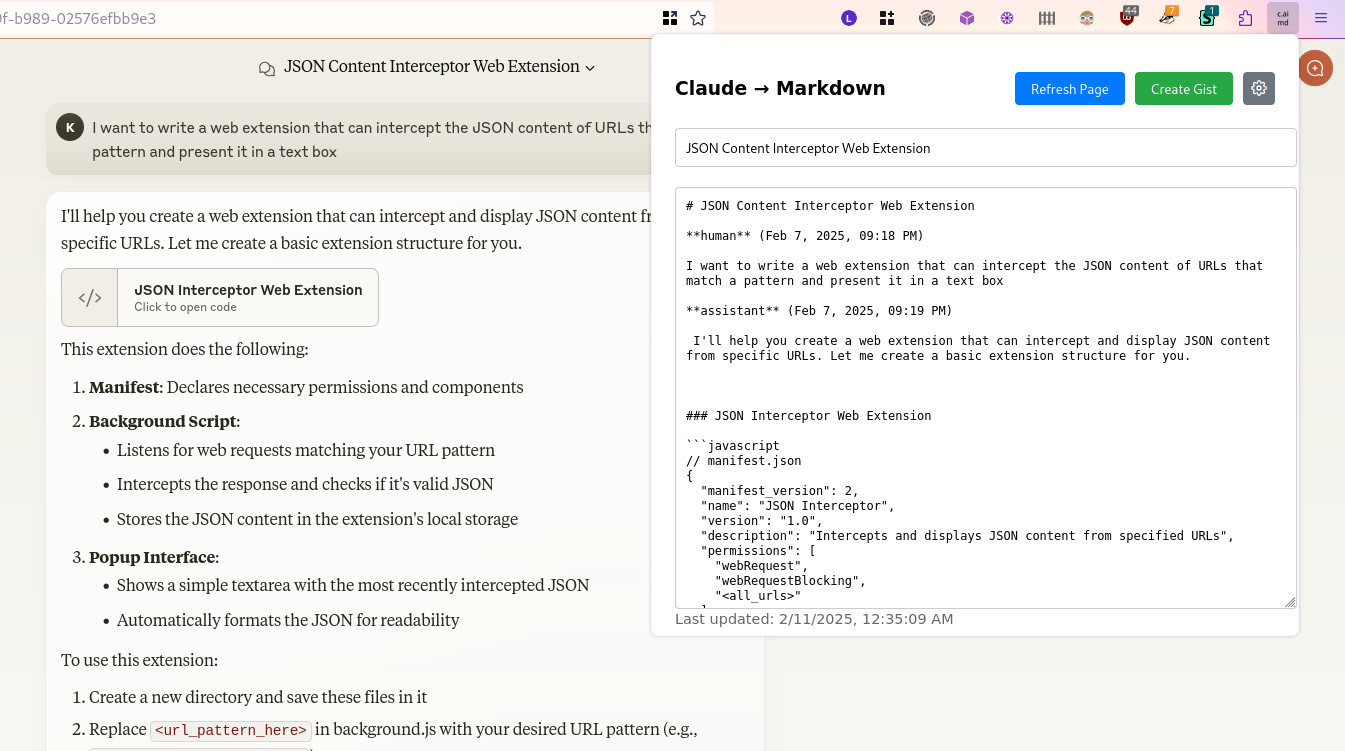
tl;dr: A new browser extension allows you to automatically export Claude transcripts to Markdown. You can install it for Firefox.
Claude is the primary LLM I use these days, but they don't have a builtin way to share your sessions, which I find pretty useful to learn from. Simon Willison had previously posted a notebook with code to convert a JSON response to a nicely formatted Markdown transcript. But the process was pretty cumbersome, you need to open up the network console, find a specific request, and then copy the JSON out of it. But on a technical level, that should be pretty straightforward to automate...right?
I asked Claude, of course, and it created a WebExtension that automatically grabbed the specific JSON response necessary, and displays it to the user. I plugged in Simon's code to turn it into markdown, and huzzah!
When you reload the tab with Claude in it, or select a different conversation, their frontend will send a request with the full JSON contents, which the extension intercepts and stores for display in the popup. It doesn't (yet) support live updating as you send new messages or replies come in.
As a bonus, I had Claude add functionality to upload the transcript as a GitHub Gist. So you can see the full transcript of the conversation used to create the extension, uploaded by itself.
This is not a super novel idea, there are other extensions in the Firefox and Chrome stores that puport to have similar functionality, but I didn't immediately find any open source ones. I also wanted to refresh my knowledge on WebExtensions; it's been seven years since I last created one.
Overall I'd estimate Claude turned something that would've taken me ~5 hours to do from scratch into a 1-2 hour project, and even then most of that time was spent manually testing and verifying the functionality versus actually writing code. The original version was not perfect, I had to make some changes like adding a content-security-policy and removing extraneous permissions. Unsurprisingly it used manifest_version 2 instead of the newer v3, even though all the code it created was compatible with the v3 requirements.
I hope this is useful for others, you can install it in Firefox and browse the source code. In theory it should be compatible with other browsers, but I haven't tested it; the .zip bundle with the extension is uploaded as a release.