It's official, I've now finished my first year of law school. As a part-time student, we were required to take torts and another lawyering seminar over the summer to wrap up the 1L curriculum.
Tort law allows people to pursue claims against others for causing harm in a civil manner. We only covered a few select torts: battery, assault, false imprisonment, and then neglience.
My professor's specialty/focus is claims where kids are harmed, so she primarily focused on examples involving kids. In our very first torts class, she showed us body cam footage of cops brutally arresting elementary school students (false imprisonment!); it was incredibly effective at sharing an understanding of how real people are harmed in the real world as opposed to an abstract, educational topic.
I'm not sharing a graphical study guide like I've done previously because I didn't end up creating one this semester. Both of our exams were open book, so I just used my notes and the resources our professor gave us.
Lawyering seminar was a continuation of last semester's simulation of child neglect, except this time the mother was being accused of also neglecting the younger sibling. We learned about educational neglect, failure to protect, and Family Court Act § 1028, which is the procedure to demand return of a child after Children's Services removes them.
In New York, every child gets their own attorney during family court procedings (siblings might share an attorney if appropriate). Close to two decades ago, the court system moved from a "law guardian" role, in which you're an agent of the court, to "attorney for child", in which you are really the child's lawyer, representing them as a client.
But we ended up serving as an attorney for a child who didn't want to go home (yet)! Between that and torts, it was a pretty intense semester; my friend dubbed it "the summer of child abuse".
We got Wednesdays off, which was nice! Unfortunately between the Knicks, the World Cup, and some bad weather, we had a number of remote classes, which I can't stand.
Next semester will be Civil Procedure, Evidence (Fourth Amendment), and drumroll Critical Race Theory. Also I'll be a Staff Editor on the CUNY Law Review.
I thought I'd take the opportunity to reflect on finishing one year by...interviewing myself. But really, these tend to be the questions everyone asks me (I don't mind!), so you can think of it as a FAQ.
What do you want to do with your law degree?
No idea. Definitely not anything family court related (see above regarding the summer of child abuse).
Really?
Really. I think I'd be interested in doing a number of things, like First Amendment free speech/expression/press, or Fourth Amendment anti-surveillance and privacy, or something tech-adjacent.
Lately something around drafting or reviewing legislation seems interesting. But I don't think I've found just exactly what I want to do yet.
Also, as you might have heard, the rule of law in the U.S. is uhhh, going through some struggle lately. So we'll see what the law is even like by the time I graduate.
Is law school hard?
It's certainly harder than any other class I've taken before, but I suppose that's to be expected for a graduate program. I find the hardest part to be balancing my time.
Normally I sign off work at 5pm sharp, eat a quick meal, start class at 6:15, and then we go until 9 or 10. Then after I get home, a bit more food and prep for the next day. Weekends are for reading for the upcoming week and whatever other homework we have.
Hanging out with friends is limited to whenever there's a holiday or by some miracle, a light reading week.
It definitely requires having a good support system; I couldn't have done it without my family and girlfriend helping me out. Whether they wanted to or not, they too learned some law school stuff when I regurgitated it to them as part of my exam prep.
Do you enjoy it?
Except for when it's exam time, absolutely. I've been interested in the law for a while, so actually learning the subtle details feels very enriching because you realize how little you knew beforehand!
Plus I just like learning. To that end, this is probably the most I've ever read in my life.
Best part is definitely the friends I've made. I think our study group is the best one (I'm being 100% objective here), and it was because we mostly happened to sit in the same row during the first week.
What's the most interesting thing you've learned so far?
I think criminal law has been the most fascinating to me, just because we all have some basic understanding of what crimes are and what's illegal, but getting to know the legal framework that underpins it all really taught me that I actually had a very poor understanding of what a crime was! To some extent this is largely academic, at the end of the day what really matters is whether the jury votes to convict.
We also learned a number of defenses to crimes, which is probably a good thing to know! My favorite is the Cheek defense, which can be used if you intentionally screw up your taxes, as long as you had a "good-faith belief" that you were doing the right thing.
However, now that you've learned about the Cheek defense, you can't plan to use it since it would no longer be a good-faith belief. You're welcome.
Where do you get boba from?
I will do a proper review eventually, but Teazzi is right across the street from the CUNY Law campus, it's quite good. The only downside is that the boba often clumps together, which means that you need to suck real hard to get the boba out, which isn't something you can quietly do in class!
During our first-ever study group session, I took the group to Teazzi and we all got boba and they said they enjoyed it. The next day before class I walk in to see my now-best friend is, entirely of her own volition, sitting there drinking boba. One of my proudest moments.
Those editors include sports fans like Kunal Mehta, 31, who began editing Wikipedia in 2006, when he was in middle school.
“It was addicting,” he said during the combination World Cup/Wikipedia editing watch party.
Mehta got his start by updating scores and creating athlete pages for the NHL’s San Jose Sharks, his home team. Now he works as a software engineer for the Freedom of the Press Foundation and edits in his spare time, often about sports. He sees Wikipedia as the “second draft” of history.
“Through all of human history, people have always tried to collect all knowledge together, that has just always been a task, like the Library of Alexandria,” Mehta said. “Wikipedia has shown that you can just do it. You just provide a blank slate for people to do it, and people will come together and work at it.”
The insane rise in scrapers across the web has affected a number of websites, including Git repository hosters. The main response has been to set up software like Anubis, which uses a proof-of-work system to limit who can access the website.
While I don't fault overburdened sysadmins for enabling Anubis to protect their servers from overload, I think it's a pretty bad solution. It introduces a delay, wastes energy, and just makes the user experience worse.
We've spent so, so, so much effort and energy squeezing out milliseconds of performance and optimizing connection times that deliberately making performance worse feels like a giant step backwards.
And the work the client does is just thrown away! It's not actually anything useful; people rightfully critized Bitcoin and (formerly) Ethereum for being wasteful for the same reasons.
So I'd like to propose a different solution, which I call "do-the-work".
In a traditional setup, it is cheap for a client to send a request to a server, the server performs some potentially expensive computations/processing and sends back a response. With scraperbots, it becomes easy for those clients to very cheaply send thousands and millions of requests that overload a server.
With proof-of-work protection (i.e. Anubis), the client it must perform its own computations, and only once it's done sufficient work, then it gets permission to send a request to the server. The server does more or less the same amount of work, it's just that the client now also has to do some work.
Do-the-work aims to invert the client-server imbalance by making the server's job cheap and forcing the client to do the more expensive computations. In other words, if you want to see some information, you need to pay the costs of calculating it by... doing the work.
Because of the way Git is designed, I think it's a great fit for this approach.
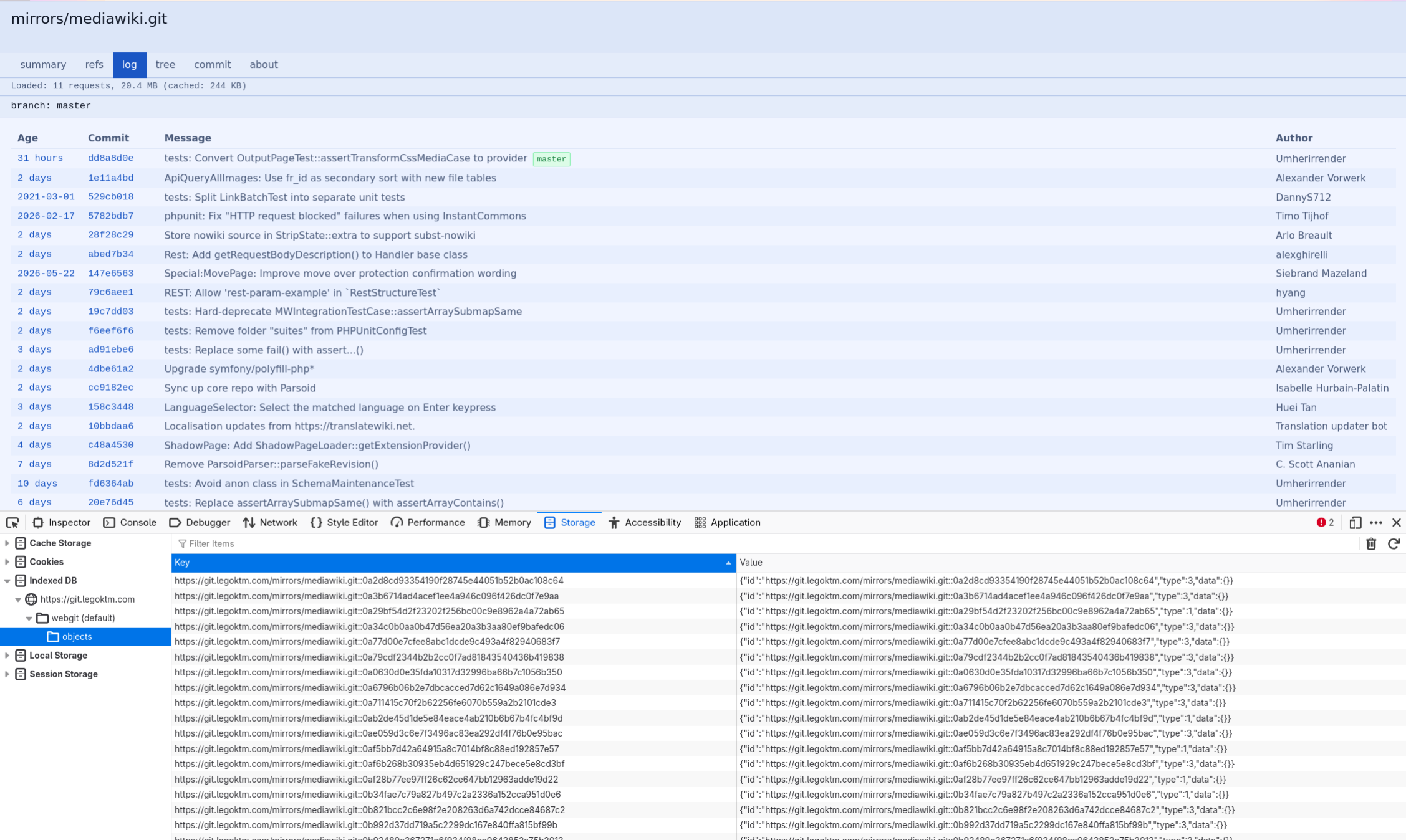
As previously teased, on git.legoktm.com I am now serving an entirely client-side Git repository viewer (source code, README), which imitates the look of cgit (used by e.g. git.kernel.org). On the server-side, it is purely static hosting of bare repositories, requiring just Apache HTTPd and a few rewrite rules.
The only thing I really need to worry about is bandwidth, but since it's now static content, it would theoretically be straightforward to put it behind a CDN.
Since most of my personal projects are quite small, I've mirrored a few larger projects so you can better see how it works: SecureDrop and MediaWiki. All of these repositories are maintained in my private Forgejo instance and I rsync them over to git.legoktm.com.
Under the hood, Git stores everything in "objects", so as long as you have some way to fetch those, then you have all the information you need to calculate everything a Git viewer needs, like file contents, diffs, a log of changes, etc. In reality it's a bit more complicated with pack files, but at the end of the day everything is an object.
Most git clients expect this to be filesystem backed, but cyberia-ng's git-async library abstracts the backend out. So I created a new backend that fetches over HTTP and stores the data in IndexedDB in your browser.
Essentially you're performing a partial git clone and then automatically backfilling missing objects as needed.
There's probably a lot more room for performance improvements, but I think it's already usable enough for small-to-medium-sized repositories. This doesn't cover everything a forge does, but if you're just hosting cgit, this should be a drop-in replacement (aside from all the missing functionality).
I think this approach can be better for privacy too. After the initial load, a subsequent load when nothing has changed on the server doesn't require fetching any more data; it wouldn't take that much more work to behave fully offline.
For now this is mostly a proof-of-concept, but I think it's probably not too far off from turning into a real thing that's usable if there's interest in that.
I finished my second semester of law school a few weeks ago, only seven more semesters to go! I'm not yet technically done with my first year since we're required to take two summer classes this year (future summers we'll have off).
This past semester was contracts (officially "Law and the Market Economy"), legal research, and another lawyering seminar. Contracts was our only doctrinal class, and I managed to rack up 72 pages of notes.
There's a lot that goes into contract law!! It depends whether you're contracting over goods or services, and then if there's some provision of law you don't like, you can just override it in the contract, except for the ones you can't.
It was definitely overwhelming at the end, here's my graphical study guide:
Notably this is quite incomplete, it's missing the entire seventh question of contracts ("When do people not party to a contract have contract law rights or contract law duties?") because I ran out of time to finish it. I also didn't include browsewrap, clickwrap, etc.
Legal research was easily my favorite class because I enjoy looking up things and perusing different sources to evaluate them, but gosh, in no just and fair world should it be legal for Westlaw and Lexis and all the other providers to lock up and put a paywall in front of the basic legal information that essentially every lawyer needs to be able to work.
Not that I ever had any doubt in what Aaron Swartz, Carl Malamud, et al. were fighting against, but I definitely have a much greater appreciation for it now that I've been on the inside of Westlaw and HeinOnline and seen what treasures of knowledge they've locked up. And how crucial they are to be able to practice law effectively.
Our lawyering seminar revolved around a hypothetical case in which a child is diagnosed with a psychiatric condition and the mother refuses to treat it, with the question being whether the mother has neglected the child. I enjoyed it more than last semester's simulation because this time we explicitly took sides — I represented ACS, arguing that she had neglected her child — and got to write persuasive briefs, followed by oral arguments on a motion to dismiss.
Summer term is torts (i.e. private right of action) and another lawyering seminar.
I had the pleasure of interviewing Brooke Vibber back in January 2021 for my story in the Wikipedia Signpost, The people who built Wikipedia, technically, which looked back at the technical history of Wikipedia to celebrate the 20th birthday.
I was not able to use all of the responses Brooke sent me for the article, but after re-reading them in light of current events, I feel it's still worth publishing five years later. Hopefully after reading this, you'll celebrate Brooke Vibber day with us today. Dankon Brooke!
What was it like getting started? Today we have a process of signing up to get a Gerrit account, a vote to give out +2 powers, NDAs for server access...what was it like then? How did you convince the powers that be (Was it Jimmy?) to give you server access?
It was all pretty loosey-goosey; if you showed up and put in good work helping out, you might well hear "yes" to getting some fairly direct access to things because that was the only way we were going to get anyone to do it!
In the earliest days I think Wikipedia ran on one of Bomis's servers so we usually would partner up with one of Jimmy's employees as an intermediary, but once we grew to dedicated servers, and then the Tampa-based hosting starting 2003-2004, it was really a core group of a few of us, many of whom are senior employees at WMF today.
As far as commit access and code review, that was very different in the early days -- we had CVS (before going SVN in 2006 or so) which meant no built-in system for local commits and pull requests, so "commit" meant roughly "merge/+2" and everyone else had to e-mail patches and me or Tim would personally review them and apply them. A lot of work!
Then in SVN times we started giving out commit access like candy, and I had to create an on-wiki code review system to help manage post-commit review...
I'm not super fond of gerrit's UI, but any flavor of pull request is a step up. ;)
My understanding is that you dropped out of film school to work on Wikipedia/MediaWiki full time - is that a fair characterization? (Or would you not prefer to be called a dropout?)
That sounds about right! :D I never quite finished my degree, and instead of taking the few more classes I needed I pivoted into work for Wikipedia which lead me into working at WMF. So, score another one for the dropouts, but I never struck it rich because we're a non-profit. ;)
What kind of programming experience did you have beforehand?
I actually grew up around programming -- my father is a software engineer and made sure my brother and I had the tools at home to learn if we were interested (8-bit Ataris when we were little, graduating up into the PC DOS/Windows/Linux worlds later). My brother and I both took well to it... though we craved that arts in high school and college -- he did some years in theater, and I worked on that film degree for a while. ;)
So when I fell back into computers, it was a world I'd never really left, but I'd also never been formally trained in it. Working on a massively-scaling-up project like early Wikipedia was a crash course in algorithmic complexity even if I didn't get all the flowerly language of big-O notation from textbooks. ;)
In February 2002, you suggested adding a WYSIWIG editor - did you ever imagine it would take as long as it did for us to get VisualEditor?
I always suspected it would be much harder to do full WYSIWIG while keeping complete compatibility with the old markup language, and I think I was proven right. :) That said, a lot of people still like the markup, so if we've succeeded at bringing it, hey! Nice.
Superprotect aside, should the rollout of MediaViewer have been as controversial as it was?
I think it should've been less controversial by far, but it also was a good example of the messaging around a rollout, and the communication between the developers, project managers, and users, was just not good. MediaViewer is great for many uses for casual readers -- its primary target audience -- but falls down in a particular way for editors who need to maintain images, not just look at them. This feedback could've been better dealt with and resolved, I think.
There's a trope that Wikimedians today are reluctant to any software change. Can you talk about some of the large software changes from the early days? How was communication with non-technical editors handled? What would be the thinking on whether to revert or leave it in a buggy state?
Honestly I think our change-conservativism issues were in full swing even in the early 2000s. We didn't make many markup changes after 2003, and only a few before that. We're now paying for that by continuing to be conservative in refusing to change things that are weird, confusing, and inconsistent because we didn't quite think through those changes and now refuse to change them again at all.
I believe you, Magnus and Tim were all college students when you got involved with Wikipedia. Do you think that was a coincidence or is there something about Wikipedia that appeals to students?
I definitely think there's an affinity between the college experience -- getting into a medium-sized world outside your house but before the big wide world and learning new fascinating things in a community of peers who want to learn and share knowledge -- and getting into the world of Wikipedia as a casual (or hardcore) editor or other contributor. :)
Today the WMF is a very professional (for lack of a better term) organization, in terms of defined processes, policies. There's an on call SRE team, etc. In the early days the servers were run by Bomis - was it like that? What kind of support did they provide? Were there power struggles between editors/volunteers and Bomis?
Bomis was very hands-off; when we ran on Bomis servers we just had some limitations in what we could access directly, and eventually I think they started encouraging Jimmy to buy separate servers when they started to become a large part of capacity. ;)
In 2012 you told the Signpost that your initial paychecks came from building "content-feed support for some third-party indexers" - I assume this was the Wikimedia update feed service? What parallels, if any, do you think this kind of API and funding model have with the new Wikimedia Enterprise project?
I think there's a direct parallel, and I'm glad to see us getting explicitly back into the business of checking in with folks who reuse our data and making sure they pay us for the privilege of the data being reliably present. :)
With 20 years of hindsight, what would you have told Magnus when he announced he was going to write the new wiki software in PHP?
Honestly, PHP was a good choice at the time. A lot of people make fun of it for its quirky syntax, function naming, and some old security misfeatures from 20 years ago, but it's an easily-approachable language with an execution model that fits web servers reasonably well and has clear ways to scale horizontally to serve more requests.
I can't really tell from the mailing list archives, but did Magnus (and later Lee for phase 3) tell people they were planning major rewrites of the software or did they just show up with it one day?
These were announced and talked about on the mailing lists. I actually feel like we were more attuned as a technical subcommunity to what was going on because there were only two lists to pay attention to, wikipedia-l and wikitech-l. ;) Magnus's code was also tested on meta.wikipedia.com (remember .com?) as I recall, before we upgraded English Wikipedia itself.
Do you think having one person do a major rewrite on their own was necessary or would have incremental refactoring have been better?
I think of Lee's rewrite as a huge one-person refactor from Magnus's early prototype. It changed a lot but had recognizably similar bones.
Ever since then we've been on the incremental refactoring track, with big internal changes being managed much more carefully.
Some of the other technology decisions like MySQL, Apache, memcached, and on have held up over time and are still actively in use today. Why do you think that is? What was the thought process when selecting those in the beginning?
These are tools that we adopted because they were tried and tested in the wild, and some of those have indeed stuck around while others have changed a bit. For instance I think we now use a mix of several web servers as well as Apache to implement the caching and TLS proxies, memcached is supplemented with redis, etc. But they've kept common protocols because they're tools that are so widely used that specialized high-performance versions that are compatible with the original exist.
And that's pretty cool!
Before you left for StatusNet, would you have considered yourself the BDFL of MediaWiki?
I'd say me and Tim Starling were kind of the dream team dual-BDFLs. :) I took a more hands-off role since I left for StatusNet and came back.
My feeling is that today neither you nor Tim (the other BDFL candidate) want that role - is that accurate? Why not? Do you view BDFLs as a good leadership model for a project like MediaWiki?
I think the BDFL role, and hero worship and cult-of-personality in general, are bad. I think communities of mutually respectful people, both developers and users, researchers and managers, editors and educators, should work together to manage their projects fairly.
Wikipedia or Wikimedia? Why?
Wikipedia has the name recognition. :)
For a piece of software named MediaWiki, it really doesn't do a great job of handling media. This is something you've worked on a ton, from ogv.js to maintaining TimedMediaHandler. Why is this an area of interest for you? Can you give a summary of your efforts? What do you think is the next area to explore for improving media?
Indeed, beyond handling image uploads we're not that great at media. ;)
I would love for us to do more work in general in this area, from audio to video to 3d models to interactive graphs and maps and diagrams of all kinds. We have some of these things, but none of them are resourced for additional by Wikimedia Foundation except for whatever research or side time interested parties like me put in.
I do hope something makes it in the budget for 2021-2022!
The main improvements I've been working on with TimedMediaHandler are:
finish removing the old jQueryUI-based Kaltura-built frontend
finish fixing bugs in the new VideoJS-based frontend, which loads less JS and has fewer modules -> thus performance benefits on first load
cleanup on the ogv.js shim which lets us play WebM and Ogg files directly in Safari -> combined with the above, this'll mostly fix video playback on iPhone
The ogv.js layer itself is one of my proudest projects, but one that's designed to become obsolete -- eventually either Safari will adopt a format we're willing to encode, or we'll adopt a format Safari can play. ;)
Future plans that I can't guarantee time for include modernizing the subtitle editor and integrating trim controls into the VisualEditor media selection. But I hope to get to them too...
Was "Contingency plans" something you were involved in? What was it like planning for a hurricane?
I think others worked on that particular list, but it was certainly something we thought about.
We only really had one or two hurricanes that directly threatened Tampa and didn't have any outages, but it really wasn't the best place for servers. :) It just happened to be near where Jimmy lived at the time, so was convenient for him to help load up the earliest servers. ;)
Are there any outage stories, or near outage stories that stick out to you as particularly funny/sad/interesting/memorable?
I think it was around Christmas 2003? We had just set up our new 64-bit database server, and had I think two or three other machines as web servers. This would've been at the Tampa data center, so all remote from where I was at the time in southern California.
Load kept going up on the db server... we weren't sure why, but it seemed to be a hardware failure... eventually it just choked up. We had to switch back to the replica on one of the lower-end boxes. We had partial service during the crash and switchover by using the file cache (is that feature still even there?) to serve out cached pages without hitting the DB.
The secondary machine had trouble too, and died a couple days later, making it a double outage.
On the plus side, this gave us lots of opportunity to push our donation link in error pages! ;)
What MediaWiki feature did you work on that you're most proud of and why?
Special:Export and the XML dump format. It's not pretty, but it gets the job done and helps tons of people build tools on top of it!
Who is someone from the early days of Wikipedia who doesn't get
enough credit for their contributions?
Lee Daniel Crocker. Lee and I don't get along on some issues so we don't talk on Facebook anymore, but I learned a lot about programming from him and the work he put in in the early days of what became MediaWiki. And that's something I'll always appreciate.
A lot of old Wikipedia and foundation work and history is in the archives of lists.wikimedia.org. But today (public) mailing lists are mostly used for announcements and discussions (at least on wikitech-l, wikimedia-l and other top lists)...do you think the shift away from mailing lists makes sense?
I think it's not surprising, but I'm not sure I like it. Maybe it's just graybeard syndrome; it was easier to have an idea what's coming down the pipe "in the old days" but at the same time it was a smaller pipe, wasn't it? Maybe email vs phab vs gitlab vs discourse doesn't make a difference. Maybe it's just whether we can have thoughtful interactions and also steer the right people to the right discussions?
You quietly stepped down from TechCom last year - why?
Quite simply, the last couple years have been really rough on my mental health. I don't have the bandwidth or the ability to consistently concentrate on the many ongoing issues I'd need to keep up with TechCom work. While I work on that, I'm concentrating on less directed research projects and underresourced things like TimedMediaHandler that don't have strict deadlines.
Wikipedia is unique in that it allows users to contribute JS/CSS directly to the site rather than requiring browserside user scripts (Greasemonkey, etc.). Do you think that was a good idea at the time? Now? I know you've also worked on exploring how to sandbox these, can you talk a little bit about that?
a) I think it's SUPER GREAT
b) I think WE DID IT SO WRONG
;)
There are two problems with letting people run direct JS in the host app environment:
if they run someone else's malicious code it can take over their account
code may use internal data accessors and methods that aren't going to stay stable, potentially breaking over time
Both can be solved by using a sandboxed environment (probably a suitable iframe). I think there's a lot of cool stuff that can be built on top of this method, with full-on APIs for accessing an editor state as a plugin, or whatever.
So far I get a lot of "yes that sounds great" but not a lot of "yes I'll assign a PM and 2 engineers to it", so this remains on my research backlog. ;)
Why is VIBBER in all caps in your username?
It is a common convention in some language communities, including Esperanto speakers, to all-caps the family name to indicate which name portion is the family name and which is the personal name. I got into Wikipedia through discovering the Esperanto edition, so that's where I created my first user name according to the local convention!
If you could, what language would you rewrite MediaWiki in and why is it Rust?
There's so many good options. ;) Honestly for its primary market (running Wikipedia) PHP scales in the right ways and has an ok combination of easy to use and handles complex paradigms you need in your big program.
Rust would be great for a micro-wiki, which runs as a small executable as a peer-to-peer service or some crazy thing. ;)
I started hosting my own Git server on git.legoktm.com in 2015 using Gogs, and in 2018, I opened it up to the world. Only a few friends and many, many spambots took me up on that offer.
I never got around to migrating the Gogs setup to Gitea, and then when the Forgejo fork happened, I was totally behind. At some point last year, because of a combination of Gogs having unfixed vulnerabilities and the excessive traffic from scrapers taking down my tiny VPS, I turned it off, letting the entire domain return HTTP 503 errors.
I expected that to be the end, thinking that I'd find some other Git hosting provider and move all my stuff there.
For various reasons, I wasn't entirely satisfied with any existing Git hosting providers and at the same time I thought it was kind of stupid that I, a pretty competent sysadmin, couldn't run my own Git host. So I took a bit of time to develop a new setup, and I'm happy to announce that git.legoktm.com is partially back.
By partially back I mean you can just clone and pull repositories, and that's it. They are served using the "dumb HTTP" protocol, which means server-side it's just static file hosting and nothing else. And there's a very basic HTML page that tells you the clone URL (example).
Most, but not all, of the repositories that used to be on git.legoktm.com are now once again clonable using their old URLs. I will backfill the remaining repositories in the next few weeks.
To the best of my knowledge, all previously working clone URLs should be supported; if something that used to work isn't, please let me know, because that's a bug. git.legoktm.com itself is still a 503 for now, I'll add a repository listing at some point.
At some point I may add a web repository viewer, but I plan to implement it fully client-side, i.e. the browser would fetch the various Git objects, calculate whatever is needed, and then display it to the user. Instead of gating on wasteful proof-of-work check, I call this hypothetical system "do the work" because you do some computation, and that work is the result you wanted!
Under the hood I'm running Forgejo, but it's only accessible via my intranet. Repositories that I designate as public are rsynced to git.legoktm.com, which I think nicely lets me run a Git server and make my repositories public without needing to worry too much about the security of Forgejo or server load.